蜘蛛爬行抓取与信息处理策略解析
- 编辑:小平SEO -蜘蛛爬行抓取与信息处理策略解析
一、知识点
1、蜘蛛都会做些什么
2、蜘蛛怎么工作的
二、蜘蛛工作三部曲
1、爬行抓取:爬行、抓取
2、数据处理:过滤、收录
3、查询系统:索引、排序
4、蜘蛛索引流程示意图:
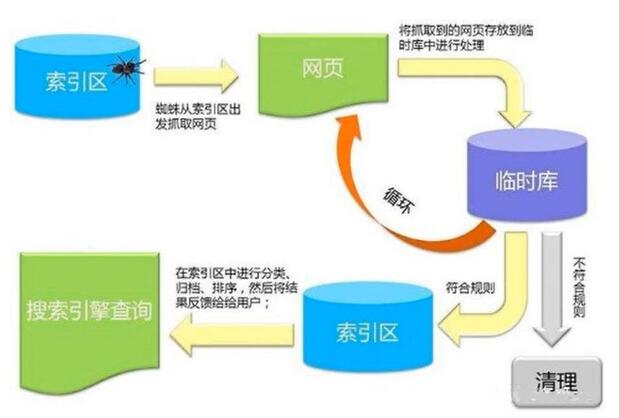
4、蜘蛛索引流程示意图:
三、爬行抓取
1、蜘蛛
(1)baiduspider
(2)robots.txt
(3)sitemap
2、链接跟踪策略
(1)两种策略并行:深度优先、广度优先
(2)权重判断
<1>低权重广度优先,高权重深度优先
<2>链接层次
<3>外链数量和质量
(3)重访抓取
<1>全部重访
<2>单个重放:针对某个更新的频率比较快比较稳定的页面
3、勾引蜘蛛
(1)网站和页面权重:层级少最优
(2)页面更新度:质量、频率(时间、数量)
(3)导入链接:外链所在网站的权重
(4)与首页点击距离:首页推荐链接
4、地址库
(1)人工录入
(2)蜘蛛抓取到的链接
(3)站长检索
5、简单检测:蜘蛛在爬行和抓取文件时也会进行一定程度的复制内容检测,遇到权重很低的网站上大量转载和抄袭内容时很可能不再继续爬行,这就是站长在日志文件中发现了蜘蛛但页面从来没有被真正收录过的原因